Article
Dec 31, 2025
The Year We Demand AI Actually Works
In 2026, it’s not enough for AI to sound right, it has to work, and be verifiably correct. This piece breaks down why most enterprise GenAI initiatives stall (workflow integration, ownership, and auditability) and what “good” looks like: domain expertise, peer validation, and traceable delivery.

2026: The Year We Demand AI Actually Works
By Victor Fiz Real
December 31, 2025
HONOLULU, Dec 31 - Earlier this year, a survey conducted by MIT's Center for Information Systems Research (CISR) on executives reported that 95% of organizations see zero return from GenAI initiatives.
Forrester Research conducted a different survey on 1576 executives during Q2 2025 that concluded that only 15% of respondents reported profit margin improvements due to AI over the past year.
These findings have sparked concern across the industry, but they paint only half the picture.
A survey conducted by Wharton's Human-AI Research group (WHAIR) in late October of more than 800 senior leaders reported that 82% of respondents use AI weekly, and 9 out of 10 believe generative AI augments their work.
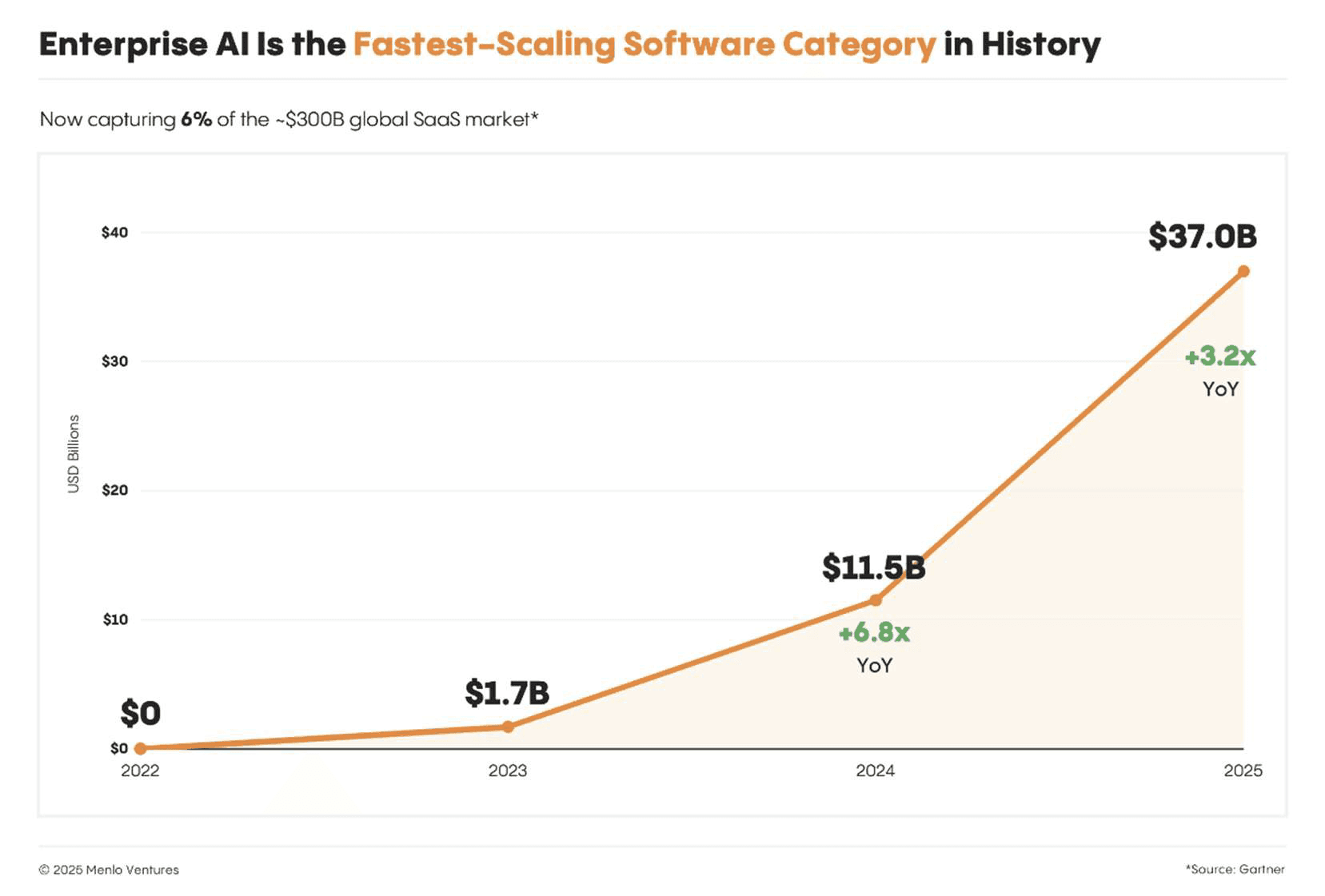
Menlo Ventures' State of Generative AI in Enterprise survey on ~500 U.S. decision-makers over the years 2023-2025
The vast discrepancy among the different surveys highlights that the measuring frameworks are inadequate, as even the respondents of all the surveys did not have solid measuring frameworks for AI utility.
However, there are points in common that help envision what some of the core issues of AI in the enterprise are today.
Most of the initiatives that these companies are undertaking are seeing long pilot phases of 9 months on average for large companies while it takes 3 months for mid-market firms. This dissimilarity is rooted in the organizational complexity and legacy systems that are inherent to bigger machines. But there is one factor that remains a challenge regardless of the size: humans.
The large failure rate of the MIT study at production scale reflects workflow integration problems, not technology limitations.
Brian Hopkins, a Forrester analyst, explained: "The tech companies who have built this technology have spun this tale that this is all going to change quickly. But we humans don't change that fast".
And faulty implementation in traditional industries is not the only factor. The way software is shipped has changed as well.
Traditional tools arrived as finished products; modern AI solutions require ongoing collaboration between the firm and the provider. In some cases, the agent is co-built. This is why the relationship between advisory practitioners and their AI partners matters; the tool improves only if both sides invest in shaping it.
"Companies need more handholding in actually making AI tools useful for them," said May Habib, CEO of Writer. For small to medium companies, maneuverability is a winning feature in implementing these solutions.
This sets up the stage for employees of said traditional industries to step up and harness the potential of AI, because it's turning out to be a significant advantage in the workforce.
Teams in some of these companies have already started creating AI implementation roles, led by professionals with a deep knowledge of their processes and operations. One example is the following job offer by Deloitte:
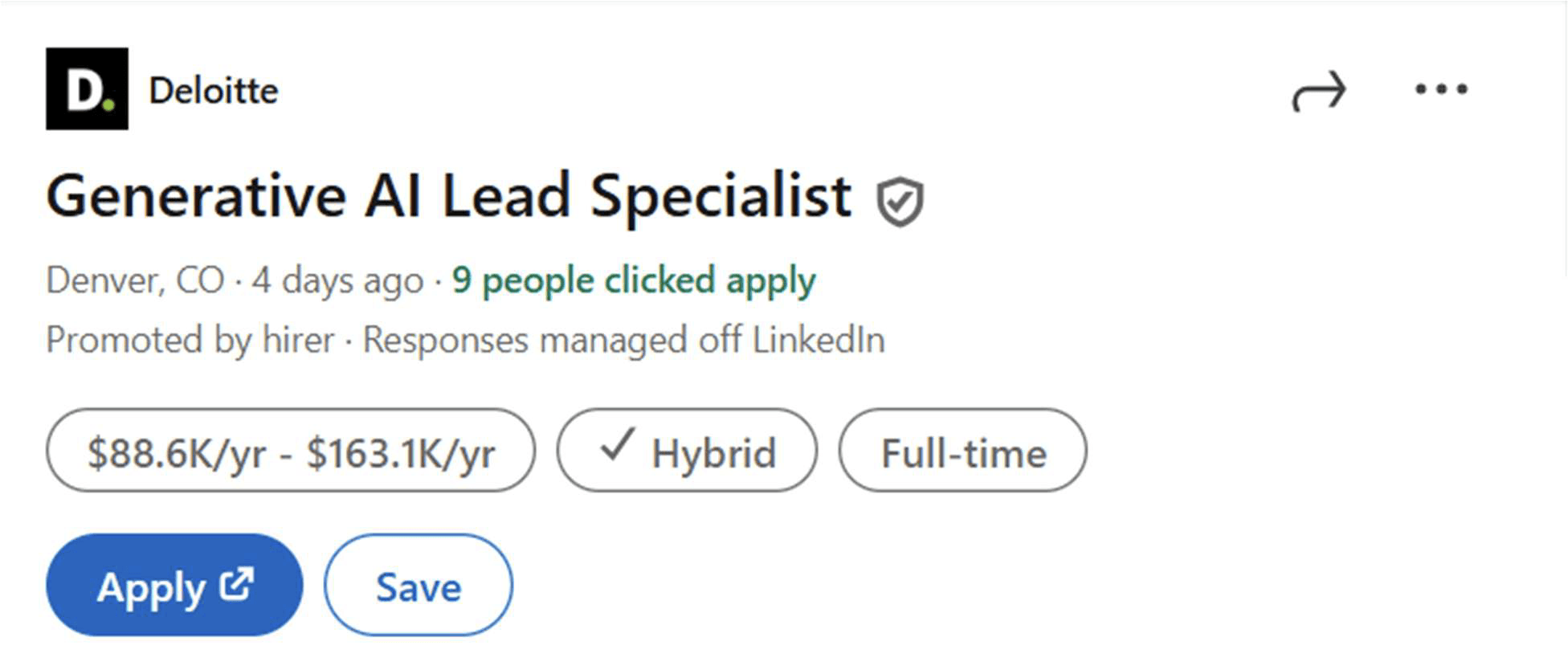
Deloitte seek consultants to manage the adoption of AI tools in their teams. Screenshot taken 12/28/2025
The idea of augmentation of skills is shared by other advisory firms such as McKinsey and Bain, who demystify the idea that AI is going to kill junior roles.
Partner at Bain Ron Kermisch says: "Rather than making the junior levels redundant, it has enabled them to do other work that has value for clients that we would not have gotten to otherwise. Most notably, exploring a broader set of options, diving deeper on second or third order implications of a decision and, perhaps most meaningfully, spending more time with clients on change management."
Mügé Tuna, executive director of employer relations at Indiana University's Kelley School of Business, brings a more disruptive view for the future of advisory: "The organization will be shifting from a pyramid to more of a diamond. The middle layer will be much larger and managing AI teams."
They both agree in saying that "consulting firms view AI proficiency as a baseline competency among MBAs, in the same way Excel was a baseline competency for data visualization in the 2010s".
These shifts manifest that companies are repricing careers around dual fluency, and there is exponential value in dominating both the AI toolkit and the underlying craft of their role and the customer.
But dual fluency alone is not enough. Without the correct guardrails, even skilled professionals fall into traps that cost reputation and revenue.
There are ways to close these gaps by design rather than by discipline: platforms that embed guardrails into advisory workflows from the start. The cost of their absence makes the case.
THE OWNERSHIP QUESTION
One of the highest impact issues that is affecting organizations in their integration of AI today is the lack of accountability and ownership in the work delivered across the verification process. Somehow, we have tended to double-check our peers' work more than the work delegated to an AI tool.
The most high-profile examples of this have involved Deloitte, which delivered reports with fabricated sources for the Australian and Canadian governments back in July and November, respectively. The latter was a contract valued at over a million USD.
"Deloitte Canada firmly stands behind the recommendations put forward in our report," a Deloitte Canada spokesperson declared, confident that the errors caught did not alter the findings and recommendations of the report.
However, this highlights that they are adopting AI before adapting their processes and workforce to handle these new tools, hindering the reputation and trust in these solutions.
A possible cause that is affecting this outcome is what has been coined Shadow AI, and that is the use of personal AI tools in the enterprise. The lag between the rollout of enterprise solutions and the use of AI tools that are easily accessible to anyone thanks to having free tier available results in part of the work happening in the dark.
This issue mirrors a familiar problem in traditional advisory: handwritten notes from client meetings that never make it into the shared record. When AI-generated content enters deliverables through untracked channels, the same thing happens.
The insight exists; the source does not. Auditability breaks.
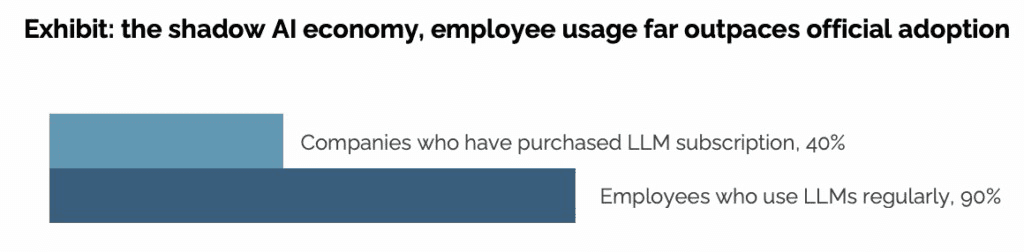
The MIT study was one of the first to find the size of the structural gap of shadow AI
But it is not only the team's responsibility to trace where information comes from; they must also confirm its accuracy. And one of the other issues that we must overcome when dealing with the probabilistic nature of these mechanisms is sycophancy: the bias towards agreeing with the user.
Models have been trained to be compliant and a little condescending with the users because we are more likely to interact in a conversation with a tool that is agreeable.
However, the main caveat is that sometimes these tools are very confidently wrong.
The extreme extent of this dynamic has a name: LLM-induced psychosis. The term describes what happens when a user can no longer distinguish between their own judgment and the model's confident output.
This year we have seen people take harmful actions because AI convinced them. But this phenomenon is not limited to the fringes.
Former Director of Engineering of the Google Deepmind team and current Founder and CEO David Budden publicly bet $10,000 on December 18th, convinced that he could find an analytical solution for the Navier-Stokes equations by January 2026 with the assistance of AI. These equations define the physical behavior of fluids and to this day most mathematicians, including Terence Tao, believe they are not solvable.

The bet between Marcus Hutter and David Budden, former colleagues at Google Deepmind
David published a formal mathematical proof on December 20th, generated with heavy assistance from ChatGPT-5.2, that has been widely regarded as invalid by the scientific community.
WHAT GOOD LOOKS LIKE
Domain expertise combined with AI fluency is what unlocks productivity gains while avoiding the pitfalls documented above.
This combination matters because critical evaluation is the central skill in working with AI. The output of these systems should never be assumed to be fully correct.
But evaluation requires something to evaluate against. The tool becomes genuinely useful only in areas where we already have the foundation to judge what it produces.
Where that foundation is incomplete, talking to peers bridges the gap. A consultant using ChatGPT to prepare for a healthcare engagement without healthcare experience cannot confidently assess whether the output is accurate. A colleague who has worked in the sector provides the reference point that the consultant alone cannot.
The last piece is traceability throughout the workflow. This requires discipline, as model providers are barely starting to integrate shared artifacts for teams to cooperate, and the chat interface is not an intuitive surface for collaboration.
Despite the challenge, with these three components in place (domain expertise, peer validation, and auditable processes) one can confidently avoid mistakes such as Deloitte's or having to reproduce work due to lack of provenance.
There is a silver lining here. Because these systems are probabilistic and require supervision, using them well means actively engaging with the subject matter rather than passively accepting outputs.
The act of checking itself is a learning process. For consultants building expertise in their domain, AI tools can become accelerants rather than shortcuts. Embracing the verification loop reinforces and deepens understanding rather than bypassing it.
For this critical thinking to thrive, it's crucial to understand what researchers have called appropriate reliance: knowing what LLMs excel at and where they fall short.
These systems are excellent at manipulating language based on the data they are trained on, but they are incapable of building new skills and knowledge. This makes them powerful tools for synthesizing, generating, and gathering information, but not so great for concluding or pattern disruption, which are recurrent scenarios in advisory work.
Recognizing this distinction allows practitioners to delegate confidently where AI adds value while identifying which gaps they must fill themselves.
Part of this realization is understanding that the good practices of software and data management are not vanishing.
Retrieval of information from repositories that are unstructured and full of dirty data is going to yield worse results in almost all cases. The technology amplifies the quality of what it works with. It does not compensate for its absence.
IBM put it simply earlier this year in a CDO study: "AI amplifies both the value of good data and the potential cost of poor data… AI agents are more likely to perpetuate and scale biases, errors or gaps in underlying datasets."
CENTRING: A DIFFERENT APPROACH
The problems outlined above - shortcut behavior, shadow AI, hallucination risk, absent feedback loops - are not inevitable. They emerge when AI sits on top of workflows rather than inside them. Centring builds it in.
Centring is a platform built for professional services. It accompanies consultants across seniorities through the delivery process, from first draft to final sign-off.
The platform serves two functions: an AI engine that generates and iterates on deliverables, and a knowledge layer that centralizes information from across the firm's ecosystem.
Where standalone models operate in isolation, Centring operates in context. It integrates with the enterprise ecosystem, including meetings, communications through Teams and Outlook, document repositories in SharePoint, and financial systems like NetSuite. This feeds the agent maximum context over the work being executed.
This integration grounds outputs in traceable, accurate information while reducing the pull toward external tools, containing shadow AI at the source.
Auditability is structural, not aspirational. Tasks are decomposed into discrete, manageable steps. Every deliverable maintains provenance.
The platform tracks which sources informed which sections, allowing reviewers to verify claims rather than trust them. When a regulator or client asks "where did this come from," the answer exists.
The agent is designed to keep the consultant in the loop for decisions outside its capabilities. This symbiotic relationship - AI handling execution, humans retaining judgment - fosters genuine ownership of the deliverables generated.
It also surfaces conflicts in the underlying information, counteracting the sycophancy that leads models to tell users what they want to hear rather than what they need to know.
The critical advantage is the feedback loop. Centring embeds review into the generation process itself. Corrections made during review are captured, stored, and incorporated into the platform's memory.
Over time, this memory accumulates the firm's definition of correctness: what "good" looks like for specific tasks, projects, and clients.
The result is compounding improvement. The gap between first draft and final deliverable shrinks, not because the model guesses better, but because it learns the partner's preferences, the firm's standards, the client's expectations.
Developed in close collaboration with advisory practitioners at Spire Hawaii LLP, the workflows reflect how consultants actually work, and how they want to work.
LOOKING AHEAD
If 2025 was the year we got used to AI, 2026 is the year we demand it actually works and know how to verify it does.
This demand matters because most people still do not understand how these systems operate. A survey by Hostinger found that 53% of Americans believe AI works like a human brain; only 14% of those familiar with the technology actually understand its processes.
The gap between perception and reality is where hallucinations go unnoticed, where sycophancy gets mistaken for agreement, where shortcuts pass for efficiency. Closing that gap requires not just better tools, but better scrutiny.
The tools are arriving. Gartner predicts that 40% of enterprise applications will integrate taskspecific AI agents by the end of 2026, up from less than 5% today. These are not chatbots.
Multi-agent orchestrators enable AI to coordinate across systems, execute complex multi-step workflows, and operate with a degree of autonomy that isolated models cannot match.
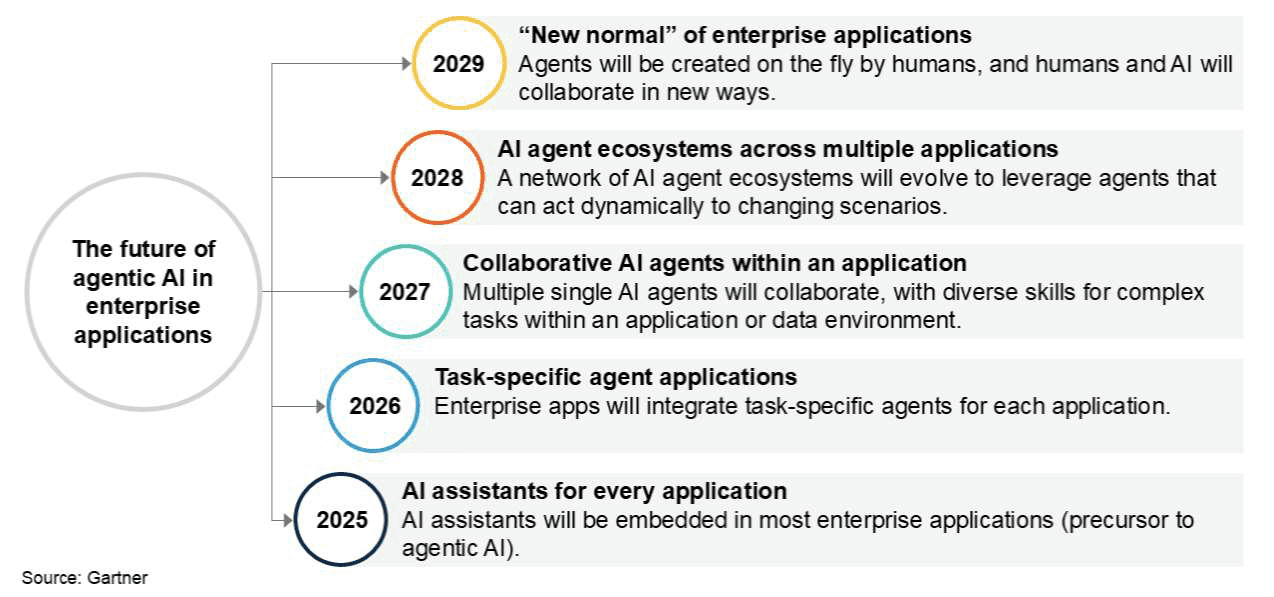
Gartner's prediction on the evolution of AI agents in Enterprise Applications (August 2025)
For advisory, this means deliverables that draw from meetings, documents, communications, and financial data without manual stitching. The architecture exists. The question is whether firms build the verification layer to trust it.
At the same time, the barrier to building custom software has never been lower. Non-technical professionals can now collaborate directly with technical teams, describing what they need in plain language and watching functional tools emerge.
This democratization accelerates uptake, but it also accelerates risk. More people building means more people building without understanding what they have built. The verification imperative extends beyond consumers of AI to its creators.
Regulation is catching up. The EU AI Act, now entering its high-risk provisions in August 2026, will do for AI what GDPR did for data privacy: establish a global baseline. Transparency requirements, conformity assessments, and mandatory human oversight will not be optional for firms operating in or serving European markets.
The Act reinforces precisely what the industry needs: auditability as infrastructure, not aspiration.
Firms that treat compliance as a checkbox will find themselves rearchitecting later. Firms that build traceability into their operations now will find compliance already met.
Whether any of this changes the fundamental dynamic between human judgment and machine output remains to be seen.
Fittingly, 2026 opens with a verdict. David Budden's bet resolves January 1st.
By the time you read this, we may know whether AI-assisted mathematics has cracked a Millennium Prize Problem or whether 'LLM-induced psychosis' could become a new entry for psychiatrists. Either way, the result will say something about the distance between confidence and correctness.
SOURCES
https://knowledge.wharton.upenn.edu/special-report/2025-ai-adoption-report/
https://mlq.ai/media/quarterly\_decks/v0.1\_State\_of\_AI\_in\_Business\_2025\_Report.pdf
https://menlovc.com/perspective/2025-the-state-of-generative-ai-in-the-enterprise/
https://www.linkedin.com/jobs/search/?currentJobId=4329233758&geoId=103644278&keywords=ai%20adoption&origin=JOB_SEARCH_PAGE_SEARCH_BUTTON&refresh=true&spellCor rectionEnabled=true&trk=d_flagship3_company_posts
https://abovethelaw.com/2025/10/law-professor-catches-deloitte-using-made-up-ai-hallucinations-in-government-report/
https://x.com/mhutter42/status/2001857421569032444
https://www.ibm.com/thought-leadership/institute-business-value/en-us/report/2025-cdo